How do we test and assure AI solutions - is one of the most common questions we hear across government right now.
AI is changing how we deliver public services. For example, the GOV.UK Chat is experimenting with generative AI to help people navigate more than 700,000 pages of GOV.UK content and find the information they need more easily. Other projects, like the Crown Commercial Service’s recommendation system, use AI to provide smarter agreement recommendations for customers based on procurement data. You can find more examples of how AI is being trialled and adopted across government in the UK Government AI Playbook. However, they are not traditional software and we can’t test them in the same old ways.
AI systems learn from data, behave in probabilistic ways and can even change over time. They might work well in a lab, but fail in real-world conditions if we don’t test them rigorously and thoughtfully.
Evaluating AI isn’t about proving it works once. It’s about continuously asking questions like:
- Is it safe, fair, unbiased and effective?
- How will it behave in real-world conditions?
- What happens when things change?
- How do we spot and fix unintended behaviour?
AI systems bring together technical infrastructure and probabilistic models. That means we need both system testing and model evaluation. Testing looks at the whole AI system (infrastructure, APIs and interfaces). Evaluation focuses on the AI model, asking how well it meets key quality attributes. Together, they give assurance that AI systems are safe, fair and accountable.
Hence, we need a framework supporting teams to embed this kind of critical thinking throughout the lifecycle of AI testing and assurance.
A shared framework for public sector teams
To help with this, the Cross-Government Testing Community has developed the AI Testing Framework for the public sector. In March, we brought people together for a workshop to pool our experience and ideas on how best to test and assure AI systems. Since then, the framework has been shaped through working group reviews and community feedback. We published a beta version in June and you can see everyone who contributed in the Review Log.
This framework offers a shared baseline for testing, model evaluation and assurance that any department can adapt to its needs. It’s designed to support everyone involved in AI projects, from policy teams scoping ideas to technical teams developing and deploying solutions.
It recognises there’s no single way to test or evaluate AI. Different types of systems (rule-based, predictive models, generative chatbots) demand different approaches.
What’s inside the framework
The framework is built around four core elements to help teams think rigorously about testing AI:
1. Principles for testing AI systems
It sets out 11 clear principles, from designing context-appropriate tests to monitoring for change over time. These principles help teams plan quality from the outset and embed responsible practices throughout.
2. Core quality attributes
AI testing and evaluation must consider things like fairness, explainability, robustness, autonomy and evolution. These attributes shape the questions teams need to ask while testing or assuring, and the risks they need to manage.
3. Continuous Defensive Assurance Model
Testing isn’t a one-off step. The framework provides guidance for every phase of delivery: planning and design, data preparation, development, deployment and ongoing monitoring. At each stage, testing produces evidence, evaluation helps to interpret it in context and assurance provides confidence that the system, or any changes, are ready to go.

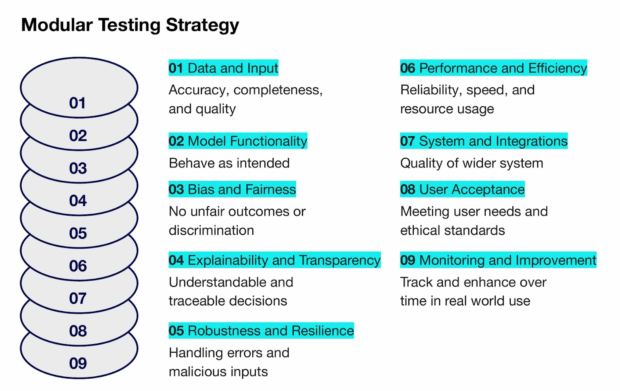
4. Modular testing strategy
Not every project needs every test. The framework includes a modular strategy that lets teams choose and combine testing activities based on the type of AI system, its use case and the level of risk involved.
Why it matters
Testing or evaluation isn’t just a box to tick.
Without good testing and evaluation, we risk:
- producing unfair or biased outcomes
- failing in unanticipated scenarios
- degrading over time without detection
- eroding public confidence in government use of AI
Good testing and evaluation helps us:
- catch problems early
- make better design choices
- build systems that are safe, fair and effective
- maintain trust in government use of AI
This framework helps us do that in a clear, structured way.
Designed for public sector use
We’ve built this framework with the realities of public sector work in mind. It:
- aligns with the UK Government AI Playbook and principles
- encourages transparency, documentation and accountability
- supports proportionate assurance, recognising that not all AI projects have the same risks
- went through a cross Government workshop and working group reviews
It’s there to help teams make informed, responsible decisions about how they test and assure their AI solutions.
Learn more
You can read and contribute to the framework here:

2 comments
Comment by David H. Deans posted on
This is a timely and well-structured overview of the challenges and opportunities in testing and assuring AI across public sector projects. The emphasis on continuous assurance will address the dynamic, evolving nature of AI systems. Moreover, the modular strategy and focus on real-world monitoring demonstrate a practical appreciation for the risks and diversity of solutions in government environments. Indeed, well done.
Comment by Anne Vaudrey-McVey posted on
Excellent blog, Mibin. The AI Testing Framework is a real leap forward—a shared, adaptable, end-to-end approach to continuous testing and evaluation of AI systems. Pragmatic, robust and timely for the Government’s AI journey, I’ll be sharing it with the CCS Digital & Data Directorate.